选择知识库类型与使用场景,配置解析与切片策略
知识库是 RAG 平台的核心实体,将一组文档、切片、嵌入与索引配置组织在一起,对外提供检索与问答能力。
创建时需要选择知识库类型,不同类型对应不同的数据和检索方式:
知识库类型选择文档搜索时,需要进一步选择使用场景。不同场景决定了检索和回答的策略:
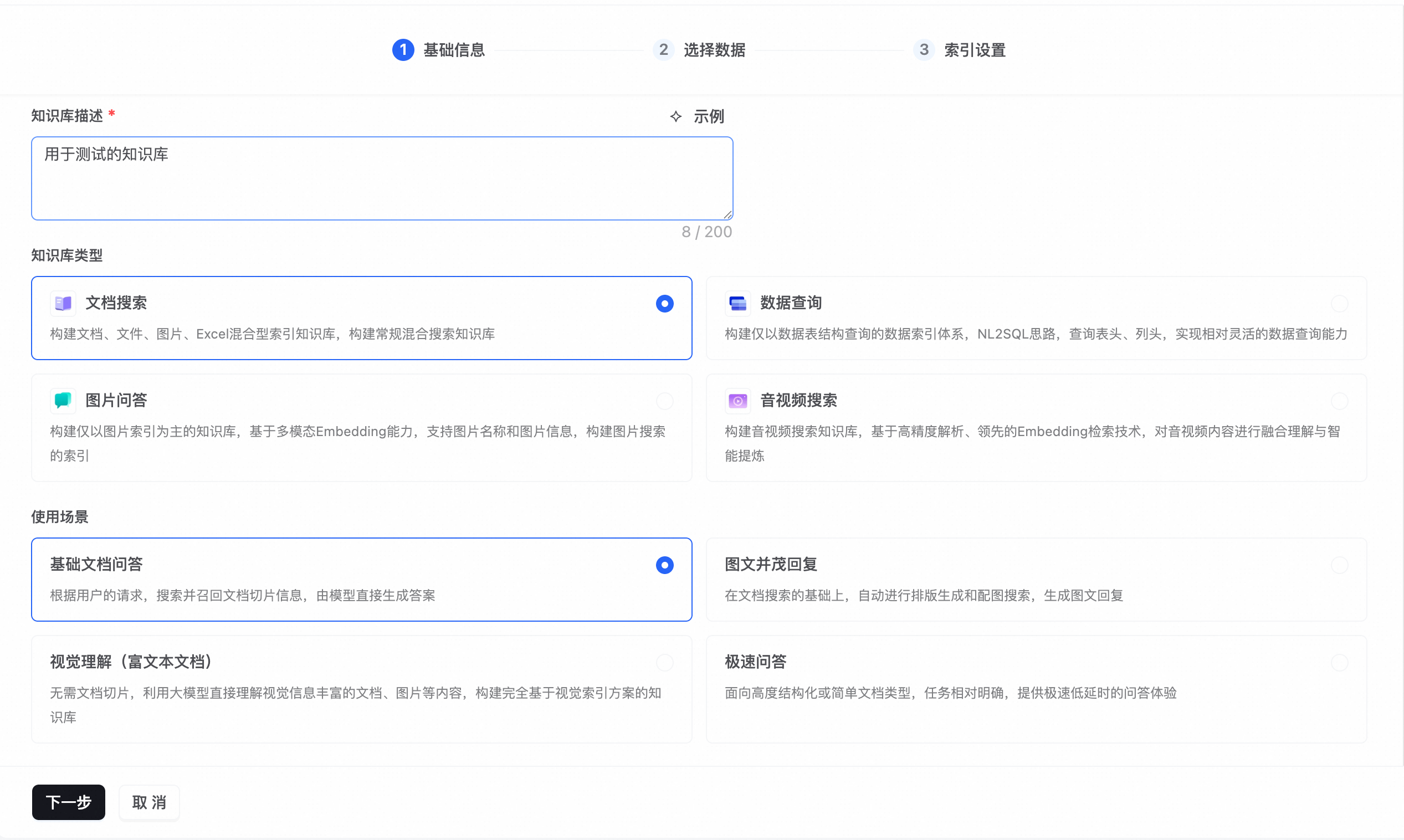 左侧选择知识库类型,选中文档搜索后右侧展示四种使用场景;其他类型无需选择场景。
左侧选择知识库类型,选中文档搜索后右侧展示四种使用场景;其他类型无需选择场景。
通过 创建知识库并导入 接口,可以一步完成创建知识库和提交数据导入任务:
知识库类型
创建时需要选择知识库类型,不同类型对应不同的数据和检索方式:
| 类型 | 适用数据 | 检索方式 | 说明 |
|---|---|---|---|
| 文档搜索 | PDF / Word / Markdown / HTML / Excel | 向量 + 关键词混合 | 构建文档、文件、图片、Excel 混合型索引 |
| 数据查询 | CSV / Excel / RDS 表格 | 自然语言转 SQL | 基于数据表结构查询,NL2SQL 方式查询表头与列头 |
| 图片问答 | 商品图 / 设计稿 | 多模态 Embedding | 以图片索引为主,支持图片搜索和图文问答 |
| 音视频搜索 | 录屏 / 培训视频 | 转写 + 片段定位 | 对音视频内容融合理解与智能提炼 |
使用场景
知识库类型选择文档搜索时,需要进一步选择使用场景。不同场景决定了检索和回答的策略:
| 场景 | 说明 |
|---|---|
| 基础文档问答 | 搜索并召回文档切片,由模型直接生成答案 |
| 图文并茂回复 | 在文档搜索基础上自动排版与配图,生成图文回复 |
| 视觉理解(富文本文档) | 无需切片,大模型直接理解视觉信息丰富的文档与图片 |
| 极速问答 | 面向高度结构化或简单文档,提供极速低延时问答 |
其他知识库类型(数据查询、图片问答、音视频搜索)没有使用场景选项。
控制台创建
1
进入知识管理
登录控制台,进入 数据接入 → 知识管理,点击右上角 创建知识库。
2
填写基础信息
| 字段 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 1–20 字,业务空间内唯一 |
| 描述 | 是 | 不超过 200 字,用于辅助筛选 |
| 知识库类型 | 是 | 文档搜索 / 数据查询 / 图片问答 / 音视频搜索 |
| 使用场景 | 是 | 基础文档问答 / 图文并茂回复 / 视觉理解 / 极速问答 |
3
导入数据
选择数据来源:
支持的格式:PDF / DOCX / XLSX / PPTX / TXT / MD / HTML / CSV 等。
| 数据来源 | 说明 |
|---|---|
| 上传文件 | 页面上传文件,一次最多 50 个,单个不超过 150 MB |
| 选择类目 | 从连接器的文件类目中导入,支持自动同步 |
| 选择文件 | 从连接器类目下选择指定文件导入 |
4
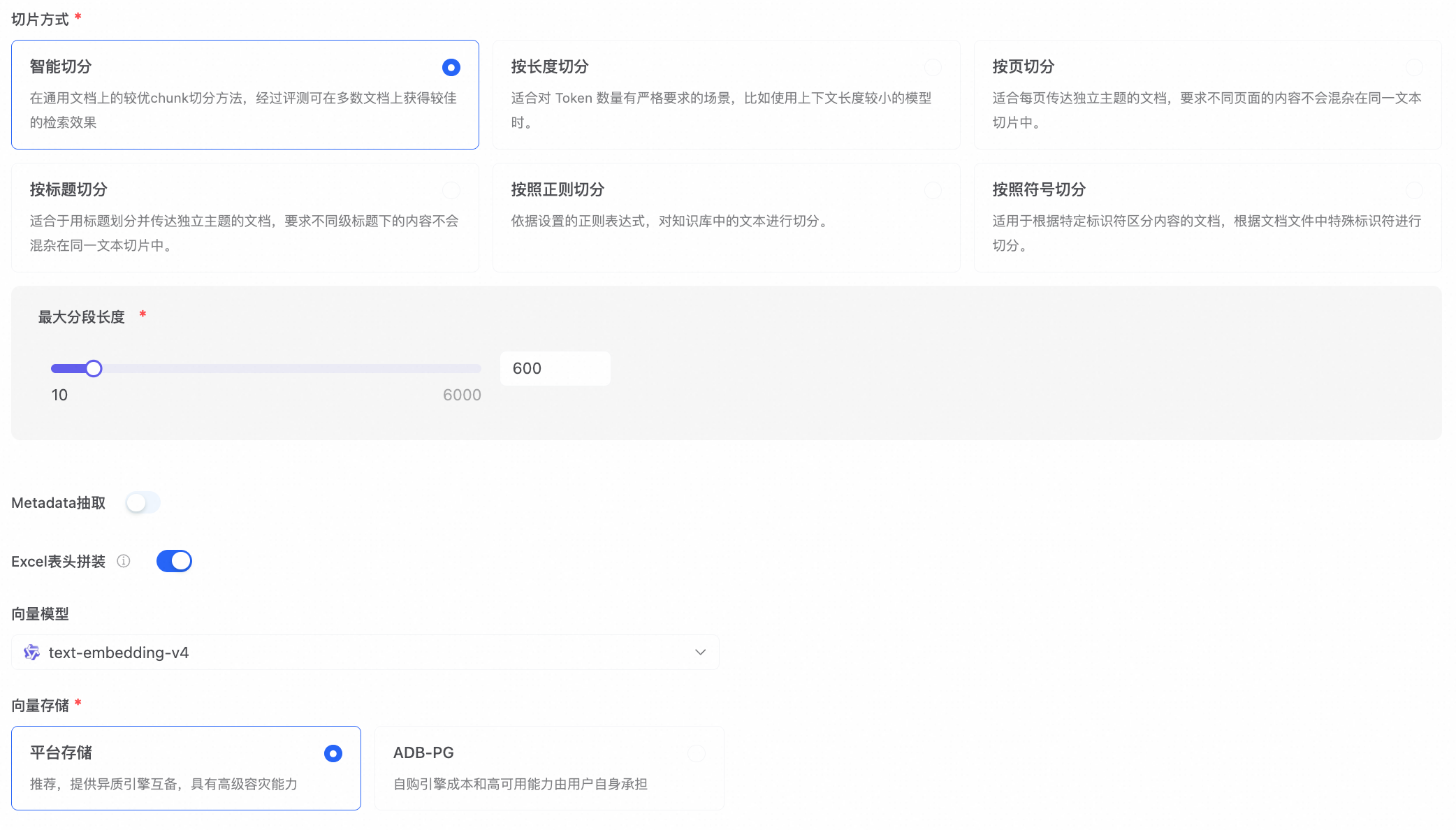
选择解析方式
默认使用默认设置,系统根据文件类型自动选择合适的解析方式,多数场景无需调整。如需针对不同格式单独配置,点击自定义设置,可选的解析方式包括:
| 解析方式 | 说明 | 适用场景 |
|---|---|---|
| 电子文档解析 | 标准文本提取 | 格式规整的电子文档 |
| 文档智能解析 | 版面级 OCR + 结构恢复 | 扫描件、复杂排版 |
| 大模型文档解析 | 调用大模型理解文档结构 | 非标格式文档 |
| Qwen-VL 解析 | 视觉语言模型 | 图文混排文档 |
| 音视频解析 | 语音转写 + 时间戳定位 | 音视频文件 |
5
6
完成创建
点击 创建知识库,系统自动完成解析、切片、向量化与索引构建。知识库状态变为 已就绪 即可检索,处理进度可在文档列表查看。
API 创建
通过 创建知识库并导入 接口,可以一步完成创建知识库和提交数据导入任务:
切片策略创建后可调整,但调整嵌入模型会触发全量重建索引。完整的容量上限见容量与限制。